How retailtrader.ai Provides Institutional-Grade Intelligence at $35 and Still Stays Profitable
At retailtrader.ai, we deliver hedge-fund caliber market predictions for $34.99/month. This pricing isn’t a loss leader; it is a structural competitive advantage derived from our “Serverless-First, Async-Heavy” architecture.
By treating market intelligence as a manufacturing pipeline rather than a real-time stream, and by replacing human analysis with GenAI, we have eliminated the overhead that bloats traditional fintech competitors.
Here is how our architecture drives profitability.
- The AI Analyst (GenAI Automation)
Competitors employ teams of financial analysts to write daily market summaries and technical briefs. This is slow, inconsistent, and expensive.
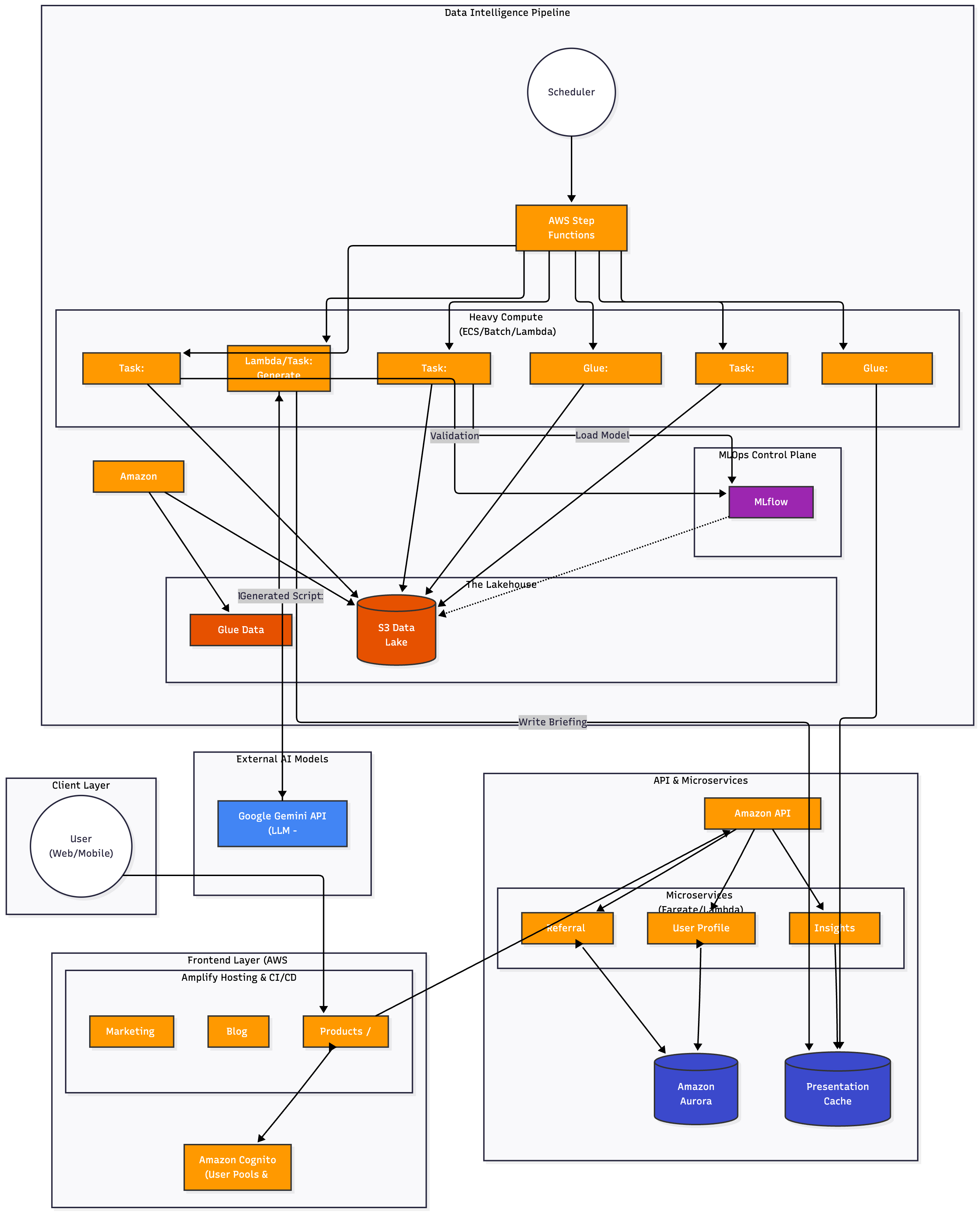
The Architecture: As shown in our Data Intelligence Pipeline, we utilize a dedicated “Lambda/Task: Generate” step within our batch process. The Workflow: This task sends raw prediction data to the Google Gemini API (LLM). Gemini instantly returns human-readable “Morning Briefings” and “Scripts,” which are then stored in the S3 Data Lake and Presentation Cache. The Cost Benefit: Instead of paying an analyst salary, we pay fractions of a cent per API call to generate thousands of personalized briefings daily.
- Algorithmic Accountability (MLOps amp; Backtesting)
Cheap advice is useless if it is unreliable. We do not just run models; we audit them before they reach the user.
The Architecture: We have introduced a dedicated MLOps Control Plane featuring MLflow. The Workflow: The pipeline includes a “Task: Backtest” block. Before any prediction is published, this task validates the model against historical data in our Lakehouse. The results are logged to MLflow. The Cost Benefit: This automated quality assurance ensures our product maintains high accuracy without the need for a manual QA team, protecting our brand reputation at near-zero marginal cost.
- The Scale-to-Zero Operational Model
Traditional platforms pay for servers 24/7 to handle potential traffic.
The Architecture: We utilize AWS Fargate and Amazon API Gateway for our core services (Referral, User Profile, Insights). The Cost Benefit: We pay only per millisecond of compute used. If no users are logging in (e.g., late at night), the compute costs for these services drop effectively to zero. We never pay for idle servers.
- Decoupled Intelligence (The Factory Model)
We do not run expensive GPU models in real-time when a user clicks a button.
The Architecture: Our AWS Step Functions orchestrator acts as a factory manager. It triggers the “Heavy Compute” tasks (Prediction, Training, Glue ETL) once per scheduled interval (e.g., market close). The Cost Benefit: We run our heavy compute infrastructure for perhaps 1 hour a day rather than 24 hours. This reduces our AI compute bill by ~95% compared to real-time streaming architectures.
- The Presentation Cache Strategy
Fetching data from a deep data lake for every user query is slow and costly (egress fees).
The Architecture: The Insights Service never touches the heavy S3 Data Lake. Instead, it reads from a lightweight Presentation Cache (DynamoDB/Redis), which is populated by the pipeline’s final Glue job. The Cost Benefit: When a user opens the app, the system performs a cheap, sub-millisecond database read. This keeps the “Cost Per User Visit” negligible, allowing us to scale to millions of users without linear cost growth.
Summary: The Profit Formula
By architecting for efficiency first, retailtrader.ai captures the margin that competitors waste on legacy infrastructure and manual labor. This allows us to pass those savings to the customer—offering a premium $35 product that remains profitable.